

Converting PDF to Excel: There are several online tools and websites with the help of which we can easily convert PDF files to Excel. However, converting the PDF files to Excel using Python is much easier. This is because, unlike online tools, we don’t have to upload files to websites to convert them. To convert the data, all that is required is to extract the file into Python. Python uses the function PDF tables API for file conversations.
In this article, let us discuss how to convert PDF files to Excel files using the PDF tables API. Scroll down to find out more.
Extract Data From Multiple PDF Files to Excel Using Python
Given a PDF file, the task is to convert the given PDF file to Excel in Python.
If you work with data, you have probably had or will have to deal with data saved in a pdf file. It is tough to copy a table from a PDF and paste it immediately into Excel. In most cases, we copy text from a PDF file rather than structured Excel tables. As a result, when we paste the data into Excel, we see a portion of text compressed into one cell.
Of course, we don’t want to manually copy and paste individual values into Excel. There is commercial software that permits PDF to Excel conversion, but it is expensive. If you’re prepared to learn a little Python, you can accomplish a reasonably good outcome with fewer than 10 lines of code.
Prerequisites:
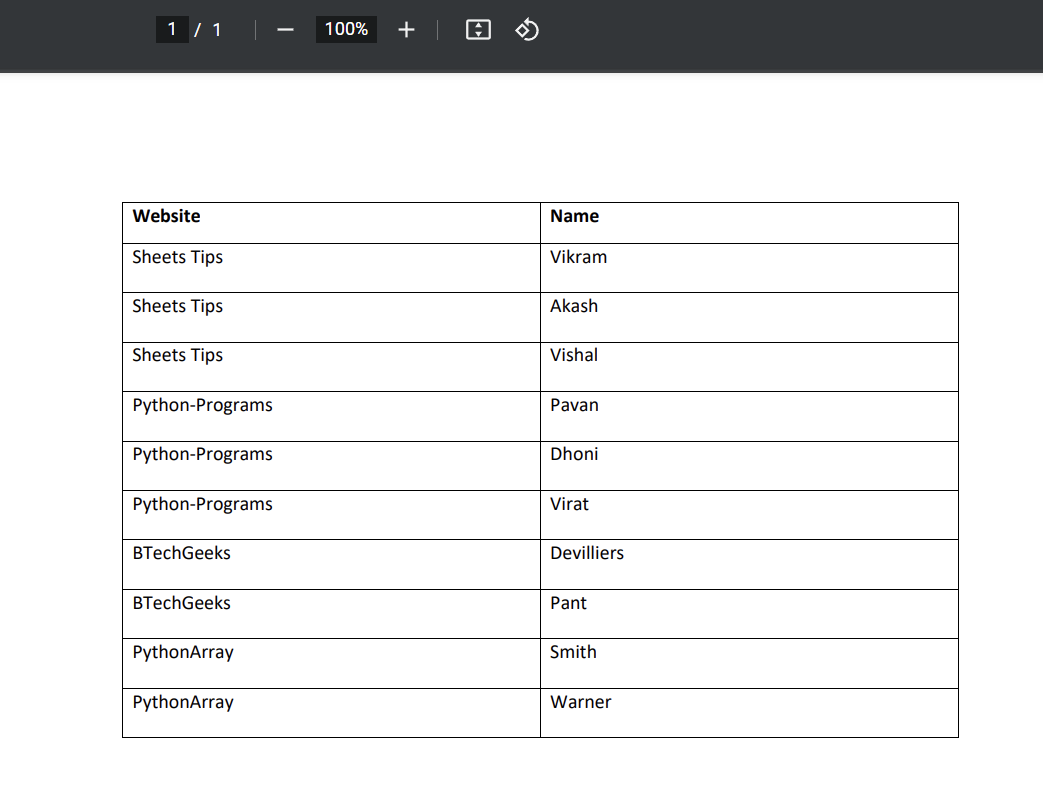
Given Pdf File:
- How to Convert PDF to Google Sheets: Free Online Conversion
- Convert a TSV file to Excel using Python
- How to Import an Excel File into Python using Pandas?
Python Program to Convert PDF File to Excel File
Below are the ways to convert the given pdf file to Excel File in Python:
Method #1: Using pdftables_api
The pdftables API Module will be used here to convert the PDF file into any other format. Because it is a basic web-based API, it may be used by any programming language.
Installation:
pip install git+https://github.com/pdftables/python-pdftables-api.git
Collecting git+https://github.com/pdftables/python-pdftables-api.git Cloning https://github.com/pdftables/python-pdftables-api.git to /tmp/pip-req-build-qfdz6fq6 Running command git clone -q https://github.com/pdftables/python-pdftables-api.git /tmp/pip-req-build-qfdz6fq6 Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from pdftables-api==1.1.0) (2.23.0) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->pdftables-api==1.1.0) (1.24.3) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->pdftables-api==1.1.0) (2021.10.8) Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->pdftables-api==1.1.0) (3.0.4) Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->pdftables-api==1.1.0) (2.10) Building wheels for collected packages: pdftables-api Building wheel for pdftables-api (setup.py) ... done Created wheel for pdftables-api: filename=pdftables_api-1.1.0-py3-none-any.whl size=5879 sha256=ddeaa9d1b7e5e0fb16cd34564d1dfa50891be0cb33ec19b70afe5c90830842af Stored in directory: /tmp/pip-ephem-wheel-cache-o0v_cktl/wheels/80/d5/88/7c51378c0b76213ee939fcb303019731948c2271fc8aab2330 Successfully built pdftables-api Installing collected packages: pdftables-api Successfully installed pdftables-api-1.1.0
After installing pdftables we need an API Key to get access.
For getting an API key visit PDFTables.com and login /signup using the email.
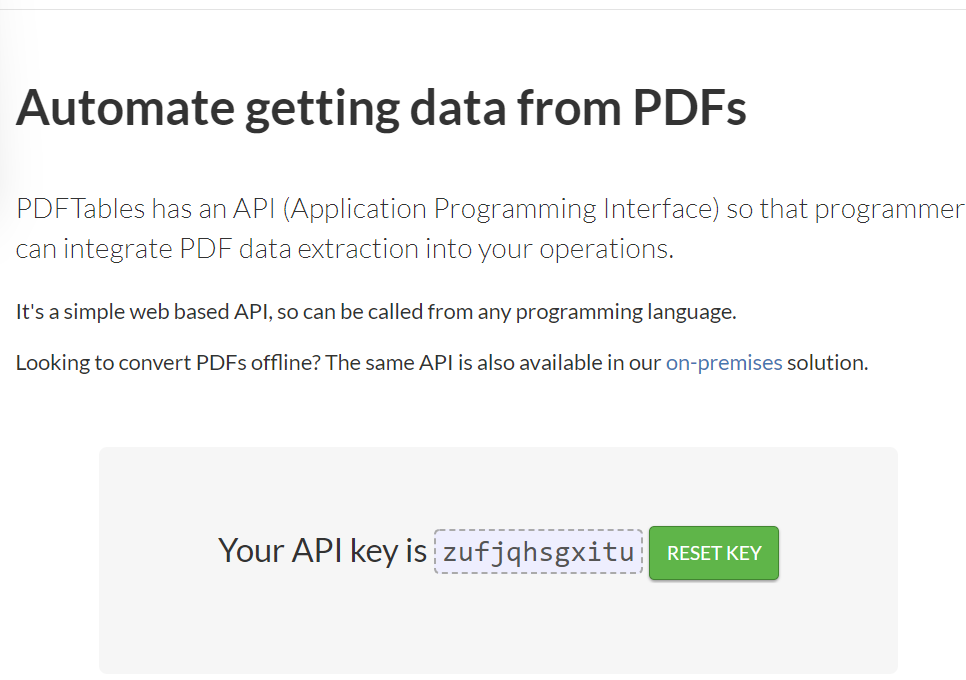
Get the API key from https://pdftables.com/pdf-to-excel-api and save it which will be used in the code.
API key Sample:
1)Converting into excel using xlsx() function
Approach:
- Import pdftables_api module using the import Keyword.
- Verification of API_KEY.
- Pass the API_KEY to the Client function of the pdftables_api module and store it in a variable.
- Converting the given SamplePdf to excel by passing the given pdf and output excel file path as arguments to the xlsx() function and apply it to the above object.
- The Exit of the Program.
Below is the Implementation:
# import pdftables_api module using the import Keyword
import pdftables_api
# Verification of API_KEY
#Pass the API_KEY to the Client function of the pdftables_api module and store it in a variable
pdf_conversion = pdftables_api.Client('zufjqhsgxitu')
# Converting the given SamplePdf to excel by passing the given pdf and output excel file
# path as arguments to the xlsx() function and apply it to the above object
pdf_conversion.xlsx("samplePdf.pdf", "resultExcel.xlsx")
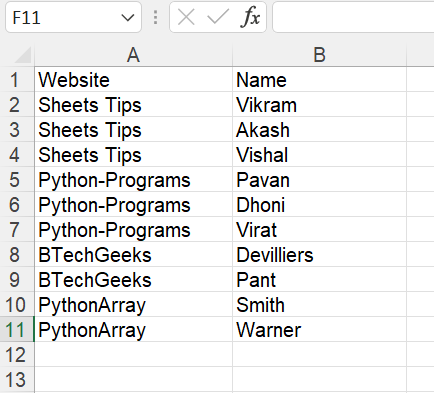
Output:
| Website | Name |
| Sheets Tips | Vikram |
| Sheets Tips | Akash |
| Sheets Tips | Vishal |
| Python-Programs | Pavan |
| Python-Programs | Dhoni |
| Python-Programs | Virat |
| BTechGeeks | Devilliers |
| BTechGeeks | Pant |
| PythonArray | Smith |
| PythonArray | Warner |
Output Image:
2)Converting into XML using xml() function
Approach:
- Import pdftables_api module using the import Keyword.
- Verification of API_KEY.
- Pass the API_KEY to the Client function of the pdftables_api module and store it in a variable.
- Converting the given SamplePdf to XML by passing the given pdf and output XML file path as arguments to the xml() function and apply it to the above object.
- The Exit of the Program.
Below is the Implementation:
# import pdftables_api module using the import Keyword
import pdftables_api
# Verification of API_KEY
#Pass the API_KEY to the Client function of the pdftables_api module and store it in a variable
pdf_conversion = pdftables_api.Client('zufjqhsgxitu')
# Converting the given SamplePdf to XML by passing the given pdf and
# output XML file path as arguments to the xml() function and apply it to the above object.
pdf_conversion.xml("samplePdf.pdf", "result.xml")
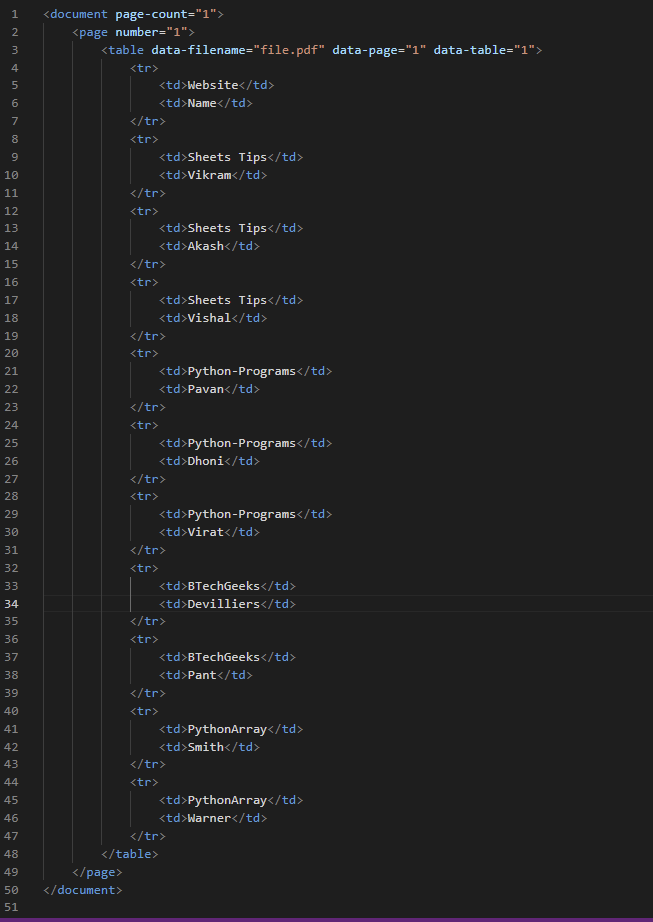
Output:
<document page-count="1"> <page number="1"> <table data-filename="file.pdf" data-page="1" data-table="1"> <tr> <td>Website</td> <td>Name</td> </tr> <tr> <td>Sheets Tips</td> <td>Vikram</td> </tr> <tr> <td>Sheets Tips</td> <td>Akash</td> </tr> <tr> <td>Sheets Tips</td> <td>Vishal</td> </tr> <tr> <td>Python-Programs</td> <td>Pavan</td> </tr> <tr> <td>Python-Programs</td> <td>Dhoni</td> </tr> <tr> <td>Python-Programs</td> <td>Virat</td> </tr> <tr> <td>BTechGeeks</td> <td>Devilliers</td> </tr> <tr> <td>BTechGeeks</td> <td>Pant</td> </tr> <tr> <td>PythonArray</td> <td>Smith</td> </tr> <tr> <td>PythonArray</td> <td>Warner</td> </tr> </table> </page> </document>
Output Image:
Method #2: Using tabula-py
We will use the tabula-py to convert the given pdf to excel file.
Installation:
pip install tabula-py
Output:
Collecting tabula-py Downloading tabula_py-2.3.0-py3-none-any.whl (12.0 MB) |████████████████████████████████| 12.0 MB 5.4 MB/s Collecting distro Downloading distro-1.7.0-py3-none-any.whl (20 kB) Requirement already satisfied: pandas>=0.25.3 in /usr/local/lib/python3.7/dist-packages (from tabula-py) (1.3.5) Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from tabula-py) (1.21.6) Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.25.3->tabula-py) (2.8.2) Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.25.3->tabula-py) (2022.1) Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas>=0.25.3->tabula-py) (1.15.0) Installing collected packages: distro, tabula-py Successfully installed distro-1.7.0 tabula-py-2.3.0
Before we begin, we must first install Java and include a java installation path in the PATH variable.
- Click here to install Java.
- Set the environment path variable to the java installation folder (C: Program Files (x64)Javajre1.8.0 251bin).
1)Excel File Without Index
Approach:
- Import the tabula module using the import keyword.
- Pass the given pdf file path and number of pages as an argument to the read_pdf() function of the tabula module and store that dataframe to a variable.
- Convert the data frame to excel using the to_excel() function by passing the arguments output excel file path and boolean variable index.
- The Exit of the Program.
Below is the Implementation:
# import the tabula module using the import keyword
import tabula
# Pass the given pdf file path and number of pages as an argument to the read_pdf() function
# of the tabula module and store that dataframe to a variable.
dataframe = tabula.read_pdf("samplePdf.pdf", pages = 1)[0]
#Convert the data frame to excel using the to_excel() function
# by passing the arguments output excel file path and boolean variable index.
dataframe.to_excel('resultExcel.xlsx',index=False)
Output:
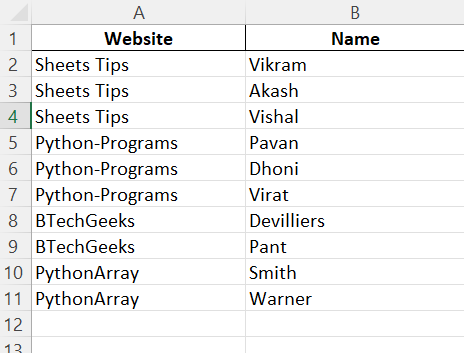
2)Excel File with Index
Approach:
- Import the tabula module using the import keyword.
- Pass the given pdf file path and number of pages as an argument to the read_pdf() function of the tabula module and store that dataframe to a variable.
- Convert the data frame to excel using the to_excel() function by passing the arguments output excel file path and boolean variable index here by default the index value is True.
- The Exit of the Program.
Below is the Implementation:
# import the tabula module using the import keyword
import tabula
# Pass the given pdf file path and number of pages as an argument to the read_pdf() function
# of the tabula module and store that dataframe to a variable.
dataframe = tabula.read_pdf("samplePdf.pdf", pages = 1)[0]
#Convert the data frame to excel using the to_excel() function by passing the arguments output excel file path
# and boolean variable index here by default the index value is True.
dataframe.to_excel('resultExcel.xlsx')
Output:
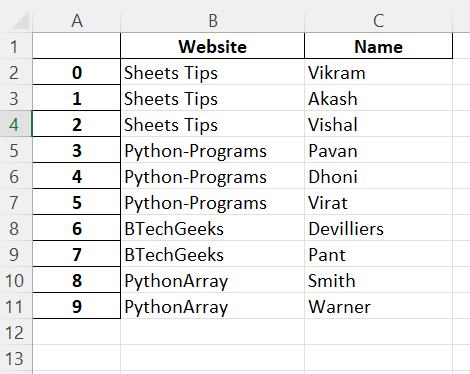
Now that you have been provided with the information on how to convert the PDF files to Excel files using Python, So, the next time you are in a situation where you want to convert PDF files to Excel, use the methods provided here to start converting your files without any difficulty.